

Sampling: You Can't Study Everyone
To discuss participant recruitment, you need to understand sampling. While sampling can sound scary, you're already applying it in your everyday life – even if you're misapplying it. If you're making soup, you might taste a small spoonful to see if it needs more salt. You figure out if the entire dish needs more salt or not and adjust it as needed. Or you might buy clothes from an online store. When you try on the clothes, you realize they don't fit well and make a mental note to avoid buying from that store in the future. In both examples, you – unconsciously – use a part to represent a whole. Sampling is effective because you can learn and make smarter decisions without tasting the entire bowl of soup or buying every item in an online store.
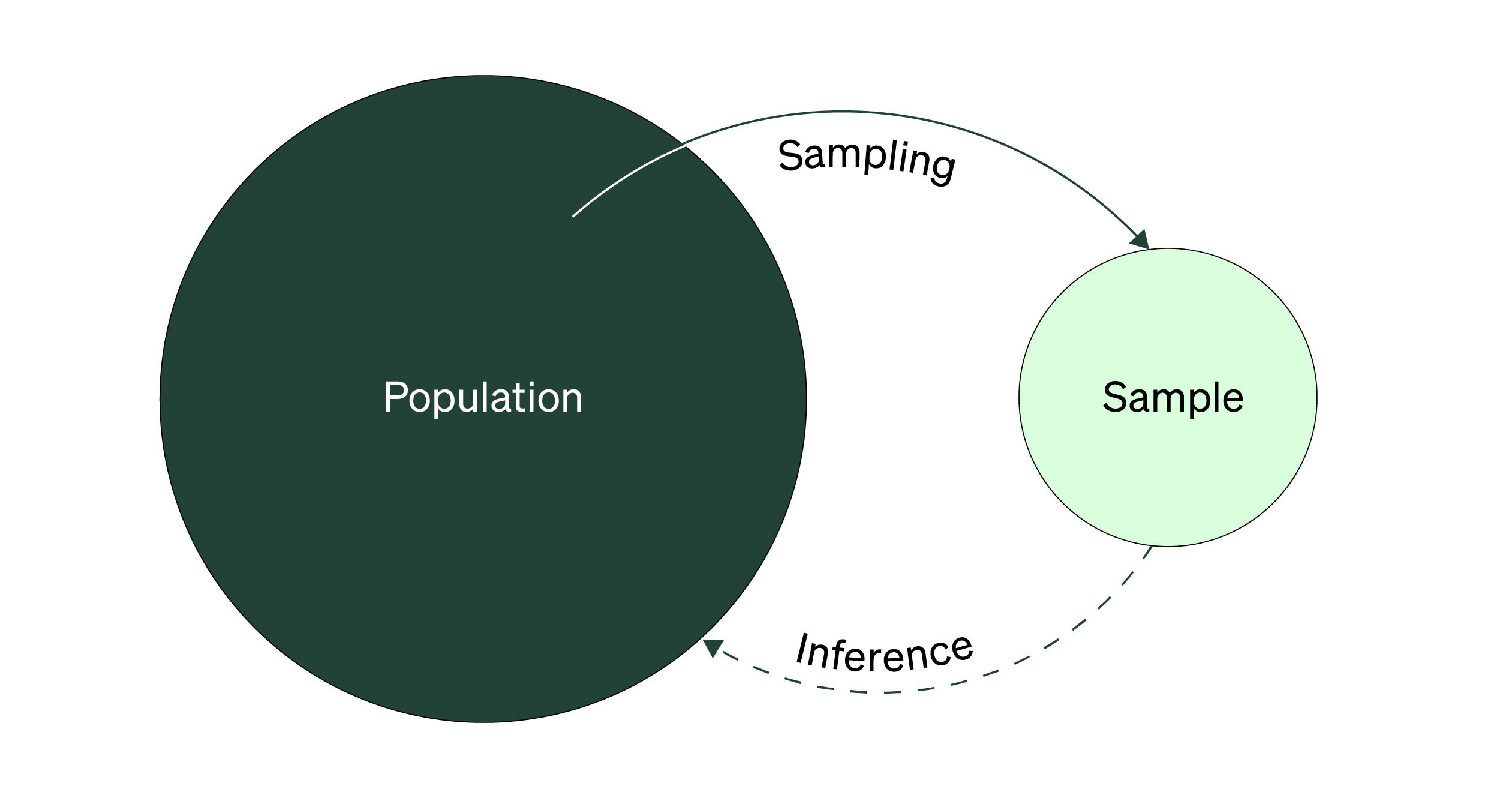
In experience research, your focus is typically on understanding a population by learning from a sample of participants. But what is your population?
Populations Are Hard to Count and Define
Let's start by saying that some people aren't more or less "valuable”. But in your research, some people might be more informative to study than others, based on your study goals.
People aren’t more or less valuable, but they can be more or less informative.
If you wanted to learn from iOS owners, you probably wouldn’t focus on recruiting Android owners. Once you know who you need to learn from, you can figure how best to recruit them. Clearly defining who you want to recruit means starting with the population.
The population is everyone who fits your requirements to participate in your study. Based on your research questions, it’ll likely be different across studies. In one, it might be everyone who used the product last month, while another study might focus on people who could use the product.
Sadly, populations are hard to define and even hard to accurately count. In the soup example from above, it's easy to understand (and physically see) what the population is. But in your research, it can be much, much harder to even define your target population.
<markdown>
# This is Markdown
| Day | Ponsonby Doctors | Viaduct Doctors |
| :--- | :--- | :--- |
| Mon 15th | 1pm - 5pm | 8am - 12pm |
| Tue 16th | closed | closed |
| Wed 17th | 9am- 5pm | 9am - 5pm |
| Thurs 18th | 1pm - 5pm | 8am - 12pm |
| Fri 19th | 1pm - 5pm | 8am - 12pm |
| Sat 20th | closed | 9pm - 1pm |
| Sun 21st | closed | closed |
</markdown>
<markdown>
# This is Markdown
| Day | Ponsonby Doctors | Viaduct Doctors |
| :--- | :--- | :--- |
| Mon 15th | 1pm - 5pm | 8am - 12pm |
| Tue 16th | closed | closed |
| Wed 17th | 9am- 5pm | 9am - 5pm |
| Thurs 18th | 1pm - 5pm | 8am - 12pm |
| Fri 19th | 1pm - 5pm | 8am - 12pm |
| Sat 20th | closed | 9pm - 1pm |
| Sun 21st | closed | closed |
</markdown>
In fact, most companies have broad, generic definitions of who their target population is. There isn’t always a one fixed, black-and-white number for the total number of people in their population-of-interest. Sometimes in experience research populations are referred to as “all users”. But does that mean all people that use the product currently, in the last 30 days, or since the lifetime of the company?
What’s a little easier to define and count are the segments a particular population gets split into. Most of the time, your recruitment focus will be on a particular segment, not your entire population.
First, Specify the Segment
Regardless of where or what you study, you can split up any hard-to-define population into smaller, uniform groups known as segments.
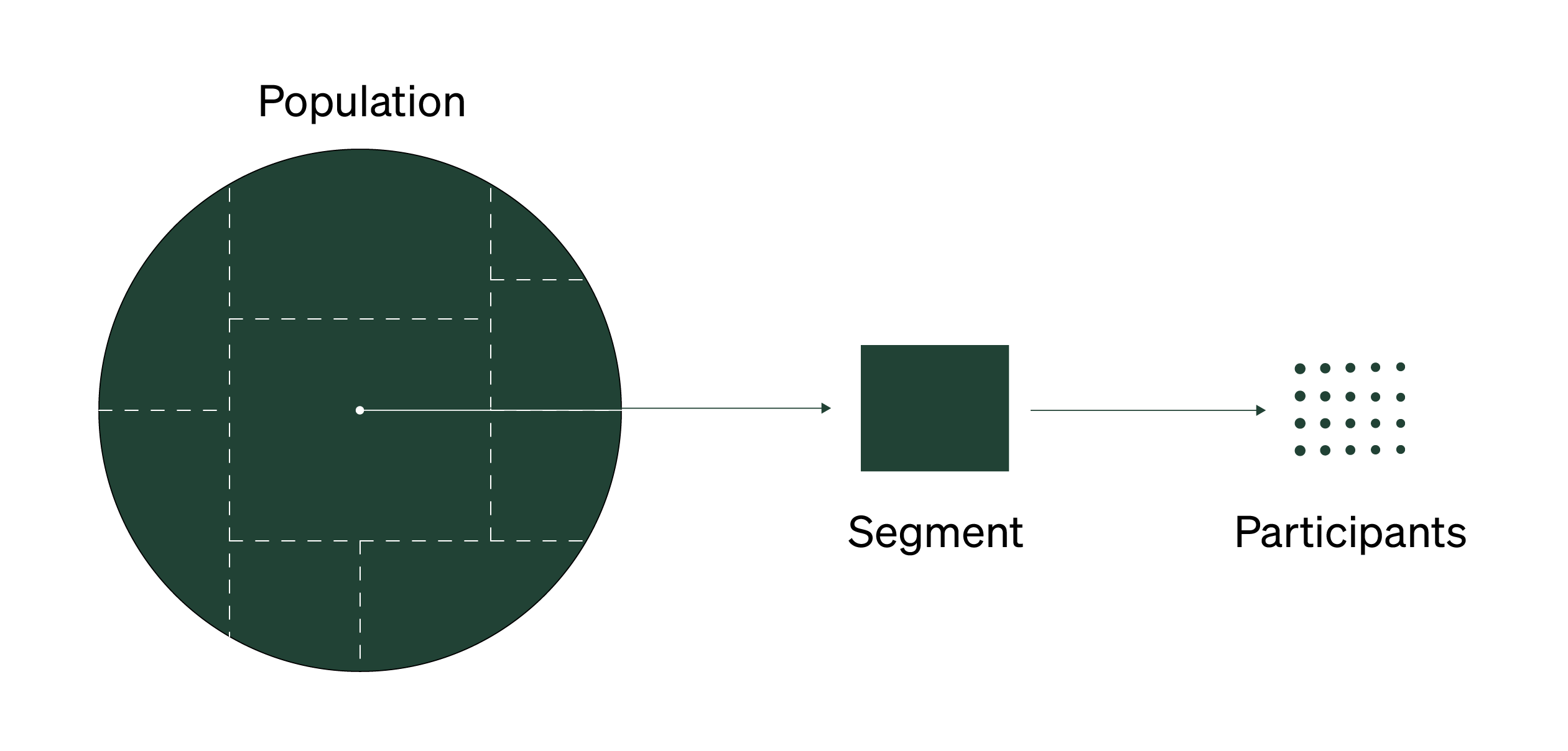
A segment is a group of people that have similar or consistent attitudes, behaviors, thoughts, or experiences. Segments can be made across a range of demographic, behavioral, and psychographic traits.
Segments really depend on the type of company or organization you do research for. If you work on internal tools or the employee experience, your segments might be role-based (e.g., inventory associate, shipping/ receiving worker, field leader, etc.) or department-based (e.g., accounting, marketing, customer support, etc.). If you work on consumer-facing products and services, your segments might be behavioral (such as lurkers, power users, sharers, etc.). If your company is international, segments like “South African market” or “Latin America region” might be be used.
As you’re reading, you might’ve noticed that segments are defined from the lens of the business and not by the people in the segment themselves. Business-centered segments can be good or bad. Good because it helps even the largest of companies align and understand who they are trying to help or service.
However, segments can be bad because companies almost always reduce every person to a segment. Not only does this practice verge near unethical research (or when people are treated only as data points), it also washes away the complexity and – more importantly – the opportunities that come from conducting research. Assuming all patterns found in your data are because someone is an “Android owner” or an “influencer” means closing your eyes to non-obvious insights in your data, outside of what segment someone is in.
You use the segment to narrow your recruiting efforts. But there’s still a problem: even if you know the segment you need to learn from, you still can’t recruit directly from a segment. People don’t self-identify as only being “Android owners ”. Knowing the segment helps you figure out who you should focus on, but you have to go one step further and connect that segment to your immediate research questions. You need to go one step further and define the Most Informative Participant (MIP).
Then, Define the Most Informative Participant (MIP)
What exactly is your team trying to learn? Does it have to do with how often someone performs a specific action? Or what types of negative emotions someone has towards the everyday experience? Within your stakeholders’ questions, expectations, and beliefs, you can notice relevant characteristics to move from general segments to the Most Informative Participant (abbreviated here as MIP).
The Most Informative Participant (MIP) is the person who holds the most accurate and helpful information to help you answer research questions and reach study goals. Similar to segments, the MIP has to be defined. But while segments can be static and unchanging over time, the MIP definition will change for every study you run.
Segments tend to be static while the Most Informative Participant changes from study to study.
Below are two quick exercises you can do to help define the MIP.

The first exercise involves the theoretical realm. In this realm, anything is possible, and you have zero constraints. If your stakeholders team had infinite resources and a 100% guarantee that you'll only study the most informative participant, who would they want to learn from? Who could sit in front of them and completely capture their attention? Who could participate so your stakeholders make an effort to observe live research sessions?

The second exercise involves something known as the "ABC" model. This stands for affect, behavior, and cognition, or put simply: What do people feel?, What do people do?, and What do people think? While this framework is commonly used to study complex social phenomena, filling it out with your stakeholders can be a simple way to understand who the Most Informative Participant (MIP) should be.
You can use these buckets and start writing in the relevant characteristics your most informative participant should have for each. Do they shop online often (aka behavior), or do they rate the app poorly (aka affect)? Or maybe it's how someone perceives themselves as a "disruptor" in their workplace (aka cognition)? You might not need all three buckets but that alone can help you narrow down what specific characteristics your sample should have.

It can also help define who your stakeholders don’t want to talk to (or, conversely, the "least informative" participant). You can use these exclusion characteristics in your recruitment screener, a way to filter and select who to learn from. If you only cared about participants in Europe, then you could set up a screener to knock out or screen out all non-European respondents. You only review and select the participants you need from a more focused list of potential participants, making your recruitment faster and more accurate. Check out this article for more help on creating screeners.
When defining and aligning the MIP definition with your stakeholders, make sure to always ask yourself:
- (1) can you recruit these participants with the time, resources, and constraints you have?
- (2) how will you confirm or validate that any potential participants actually fit the MIP definition?
When you define the "most informative" participant, you increase your focus and avoid wasting your limited resources. But there's a serious issue here: how do you know who you learn from represents the population or segment you’re trying to understand?
Sample Composition & Representativeness
A goal when sampling is to get a sample that best reflects the population or segment on any relevant characteristics. The characteristics of who or what is in your sample is known as the sample composition. These characteristics could be focused on specific demographics, segments, behaviors, and more. You use a sample’s composition as a way of checking sample representativeness.
A representative sample is a group of participants or units who reflect or mimic a population or segment’s important, relevant characteristics. Representative samples are powerful because you're essentially recreating the entire population or segment with your sample. It’s the most efficient way to answer your research questions using the least resources and participants possible. Representative samples also make your generalizations more credible and accepted (see Handbook 7, Topic B for more on external validity and generalizations).
To get the best possible representative sample, you need a few things:
Representative Sample Requirements
- Reliable knowledge about the population or segment (aka how many people share specific and relevant characteristics or traits)
- A way to contact people in the population
- Some form of random sampling (discussed more in Handbook 3, Topic C)
- A "large" enough sample size (discussed more in Handbook 4, Topic A)
Commonly, experience researchers use basic demographic variables (such as age, gender identity, socioeconomic status, etc.) to help create a representative sample. But, today, a more popular variable is behavior. For example, suppose if you know that your target overall population or segment shares a lot of social media content. In that case, you'd want to make sure to recruit participants who also share a lot of content.
A representative sample is one where the people in your sample and the people in your population/ segment are as similar as possible.
Relevant behaviors will be different based on where you work. You should learn about any product analytics capabilities your team uses (such as Google Analytics) to see which behaviors are recorded and how. You can also ask about behavioral metrics during regular team interactions, stakeholder interviews, or review them when conducting desk research.
Guide #1: Conducting Desk Research
Guide #2: Conducting Stakeholder Interviews
When you focus on a particular population or segment, you make it more likely you recruit with intention and speed. To go even deeper, let’s discuss the various stages of sampling.
- Sampling with and without replacement
- Study inclusion/exclusion criteria
- Sampling theory; sampling techniques
- Sampling distribution
- Inclusion probability (pi-i)
- sample mean; sample proportion
Resources locked during public beta.
